前言
前段时间做毕设搞了个 AI 对话界面,但是一直都不满意。然后现在答辩完了,继续来搓一个好看点的 AI 对话界面。也练一练自己 JavaScript 和界面排版技能。
平时 AI 用的 Gemini 最多,也挺好看的,就选它来造了!
准备
Gemini API Key:半个月前部署玩过 my-neuro 然后申请的 API Key,免费方案已经非常够用了。
申请 API Key 网站
开始
第一步:制作大致布局
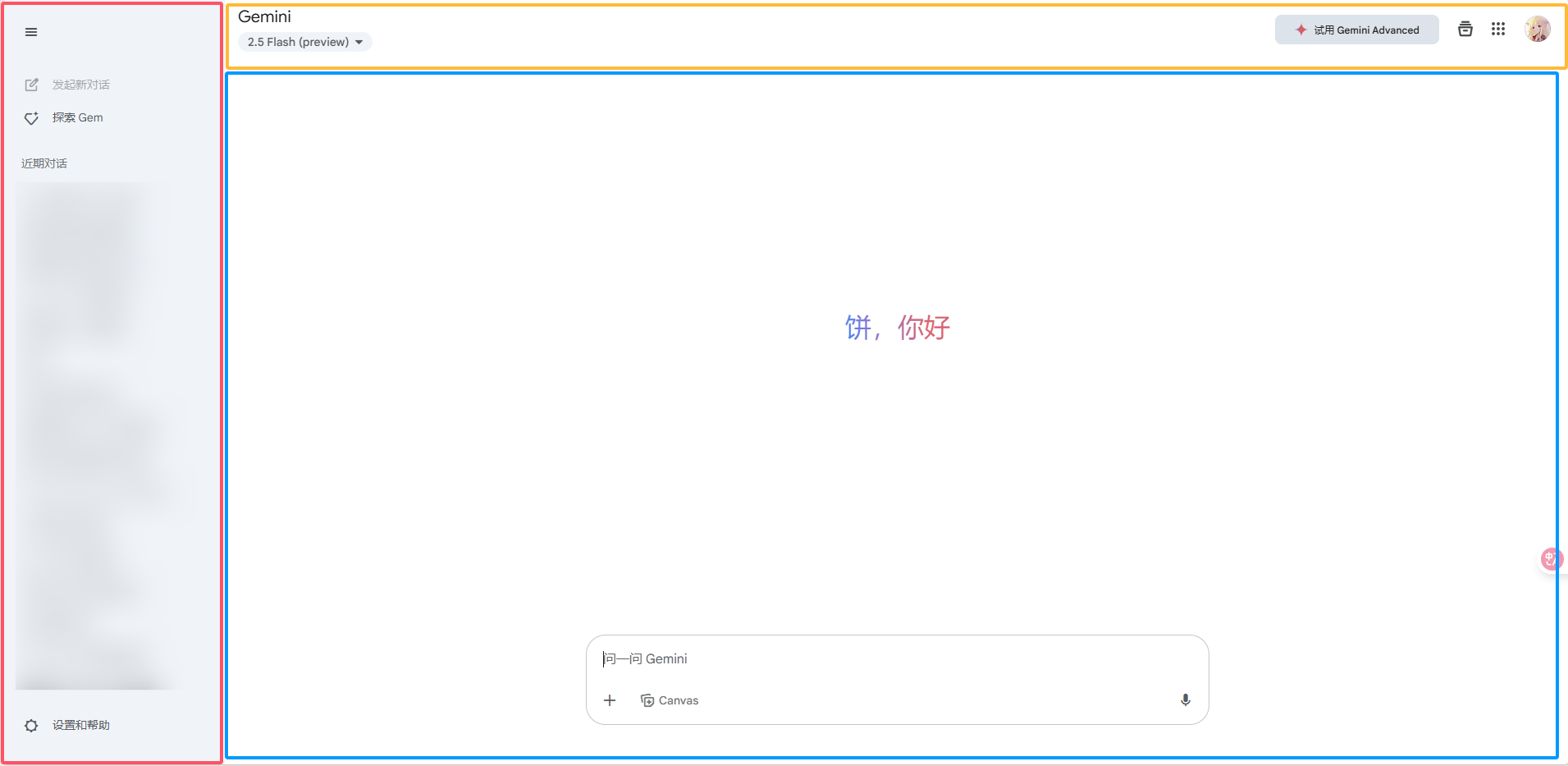
观察 Gemini 网站的布局,可以分作三大块。
![image]()
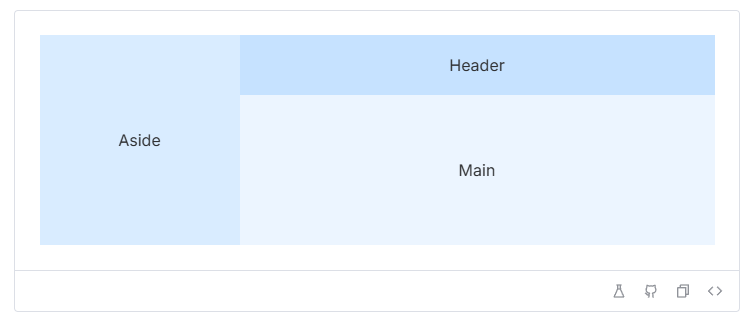
这里我用了 Vue 框架来写, Element-Plus 的布局容器,非常方便。能帮我快速划分工作区块。
![image]()
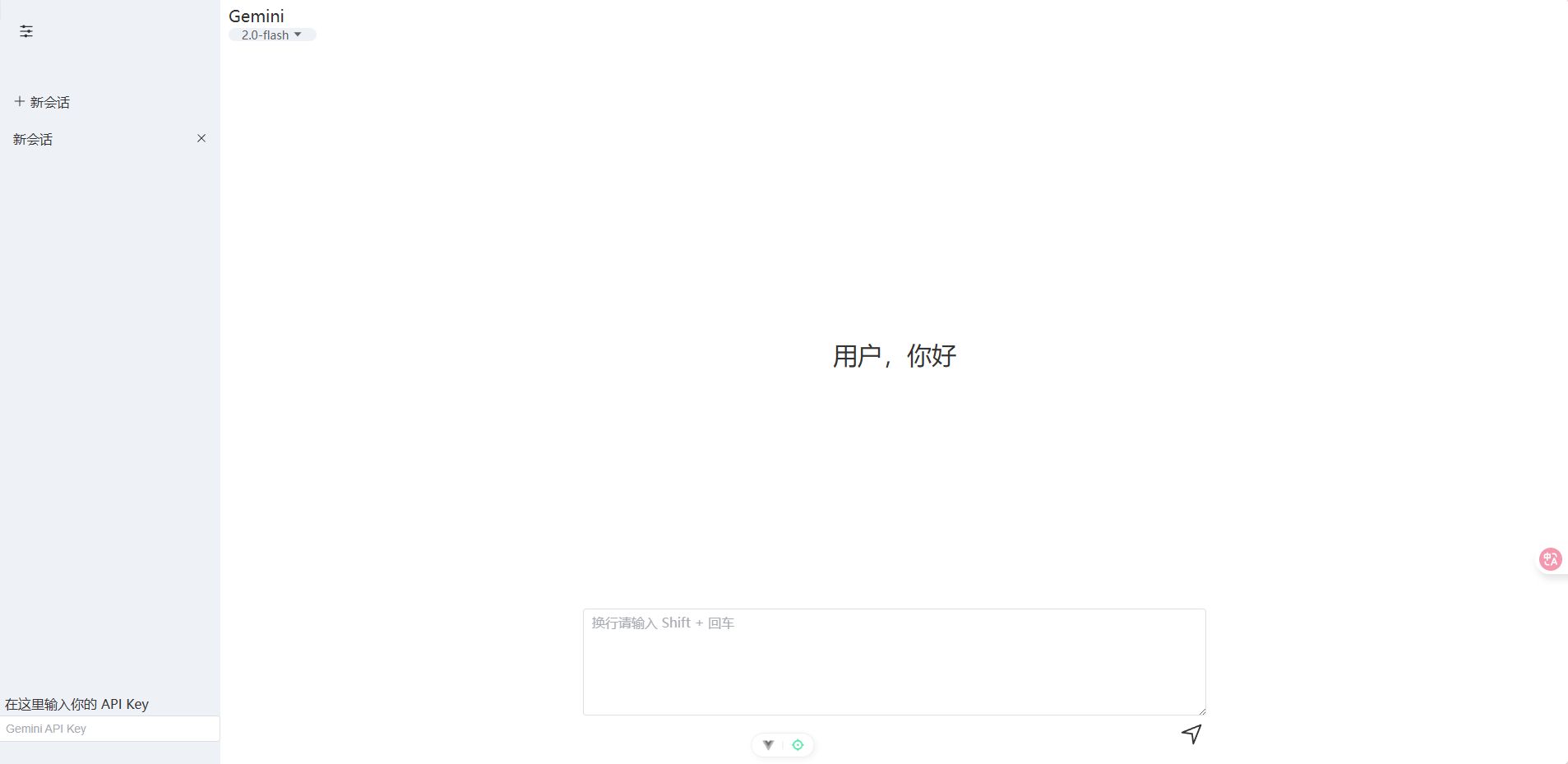
成品如下,制作的时候也是花了很多时间,自己一点点对着 Gemini 网站扣了出来,也温习了一下以前学的元素布局方法。
制作的时候忘记组件化制作,在父组件一股脑往下做。结果一大坨屎山出来了
![image]()
第二步:实现调用接口
然后就是处理调用接口部分了。第一步,先来官网找文档。
Gemini API Key 使用方法
模型功能有很多,首先就来实现第一个最基本的文本对话功能。
![image]()
既然是对话聊天 AI ,那么上下文关联很重要。这里官方称为 多轮对话(聊天),而且得选择流式传输,不然得傻傻等半天。
官方提供的使用方式很清晰,文档已给出链接、调用方式、头部、请求体。
将用户和 AI 的消息全部放在请求体内,以 POST 的方式对调用链接进行流式传输请求。准备一个空的消息数组将返回的数据进行拼接。处理流式文本,提取文本信息。
通过查看响应数据,可以找到结尾关键字为 "finishReason": "STOP" ,其余文本均现将开头的 data: 去掉,转成标准 JSON 格式后,提取 text 里的内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
data:
{
"candidates": [
{
"content": {
"parts": [
{
"text": "模型,由 Google 训练。\n"
}
],
"role": "model"
},
"finishReason": "STOP"
}
],
}
|
获取接口返回的数据,然后将其中的有效文本提取并追加到 messages 内。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| try {
const response = await fetch('https://generativelanguage.googleapis.com/v1beta/models/gemini-' + model.value + ':streamGenerateContent?alt=sse&key=' + apiKey.value, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
contents: messages.value.map(m => ({
role: m.role,
parts: [{text: m.content}]
}))
})
})
if (!response.ok) {
throw new Error(`请求失败,状态码:${response.status}`)
}
const reader = response.body.getReader()
const decoder = new TextDecoder()
messages.value.push({
role: 'model',
content: ''
})
const currentIndex = messages.value.length - 1
const processText = async ({done, value}) => {
if (done) {
loading.value = false
return
}
const chunk = decoder.decode(value, {stream: true})
if (chunk.startsWith('data: ')) {
try {
const jsonStr = line.replace(/^data: /, '').trim()
const data = JSON.parse(jsonStr)
const text = data.candidates?.[0]?.content?.parts?.[0]?.text || ''
if (text) {
messages.value[currentIndex].content += text
await nextTick()
scrollToBottom()
}
} catch (e) {
console.warn('解析错误:', line)
}
await reader.read().then(processText)
}
await reader.read().then(processText)
saveMessages()
} catch (error) {
loading.value = false
messages.value.push({
role: 'model',
content: `❌ 请求失败:${error.message}`
})
}
|
输出消息部分使用了 v-for 循环输出存在 messages 里的文本内容,通过读取 role 里面的角色身份来分配响应的样式
1
2
3
4
5
| <div v-for="(message, index) in messages" :key="index" :class="message.role">
<div class="bubble">
<span v-html="md.render(message.content)"></span>
</div>
</div>
|
可以看到消息如期展示出来
![image]()
第三步:消息持久化
虽然上面是实现了 AI 对话,但是一刷新页面就会导致对话消失,没法保存。这里我使用 LocalStorage 进行长久存储。
首先,创建出会话 ID。为了让每个会话 ID 尽可能不一样,使用了时间戳来进行制作,防止快速点击新会话,短时间内时间戳没变化导致会话 ID 一致,在末尾又加了 0-1000 的随机数。
1
2
| const now = new Date();
const chatId = `${Date.now()}_${Math.floor(Math.random() * 1000)}`
|
然后按照以会话 ID 为 Key ,消息内容为 Value 存储在 LocalStorage 中实现持久化。
侧边栏选择会话通过 v-for 遍历输出标题,标题的内容为用户说的第一句话的前 10 字,想像官网那样做第一句的总结的,不知道应该怎样实现。
然后也按照以 chats 为 Key ,会话 ID 和标题内容为 Value 存储在 LocalStorage 中实现持久化。
最后将加载函数放在生命周期钩子 onMounted 中,每次加载页面的时候就读取存储的内容。
最后
其实最开始写到流式读取的时候用的 ChatGPT 写的,后面逐步修改多余的逻辑简化了 30% 多,也是像这个贴子里的回复说的一样:“虽然它可以工作,但是会写很多糟糕的代码,通常比你需要的行数要多的多。”
点我前往
修改的过程也是学习的过程,理解透了的感觉很舒服。